
Pre-Requisites
To begin, please ensure you have followed the instructions in the first and second articles to set up Kafka and SQL Server Docker containers. These initial configurations are prerequisites for this deployment.
- Mastering Kafka Deployment with Docker in 10 Minutes
- Optimizing Microsoft SQL Server Deployment in High-Performance Docker Environments
JDBC Source Connector
The JDBC Source Connector is a component of Kafka Connect, designed to enable streaming data from relational databases into Kafka topics. It facilitates real-time data integration by continuously polling a database and publishing the data to Kafka, making it a crucial tool for building data pipelines, ETL processes, and real-time analytics systems.
Key Features
- Database Compatibility:
- The connector is compatible with a wide range of relational databases, including MySQL, PostgreSQL, SQL Server, Oracle, and others that support JDBC (Java Database Connectivity).
- It uses JDBC drivers to connect to databases, allowing for flexibility in connecting to various database systems.
2. Flexible Data Extraction Modes:
- Bulk Mode: The connector retrieves the entire table data in a single query. This mode is simple but not suitable for tables with large amounts of data, as it might overwhelm the Kafka topic or miss updates after the initial extraction.
- Incrementing Mode: Data is extracted incrementally based on a specified column (usually an auto-incrementing ID). The connector tracks the last processed ID and only fetches rows with higher IDs in subsequent queries.
- Timestamp Mode: Data is extracted based on a timestamp column, where the connector fetches rows with a timestamp greater than the last processed timestamp. This is ideal for tables that are frequently updated.
- Timestamp+Incrementing Mode: Combines both timestamp and incrementing modes. It first uses the timestamp to filter rows and then applies the incrementing logic to ensure no duplicates are processed. This mode is useful for complex use cases where data is frequently updated and new rows are added.
3. Polling Mechanism:
- The connector uses a polling mechanism to query the database at regular intervals (defined by
poll.interval.ms). It continuously checks for new or updated data based on the mode of operation, ensuring that the Kafka topics are updated in near real-time
4. Schema Management:
- The JDBC Source Connector automatically generates schemas for the data being ingested into Kafka. It can also infer the schema from the database table and propagate schema changes, ensuring that Kafka consumers can easily deserialize the data.
- Schema changes in the source database (e.g., adding new columns) can be propagated to Kafka topics if configured correctly.
5. Fault Tolerance and Offset Management:
- The connector stores its offset (the last processed row or timestamp) in Kafka or a local file (depending on the setup), allowing it to resume from the last position in case of a failure or restart. This ensures that no data is missed or duplicated during recovery.
- The offset management is crucial for maintaining the consistency and reliability of the data stream.
6. Custom Query Support:
- The connector allows you to specify a custom SQL query instead of directly reading from a table. This is useful for complex transformations or when joining multiple tables before sending data to Kafka.
7. Partitioning and Parallelism:
- The connector can be configured to split the workload across multiple tasks, allowing parallel data extraction from the source database. This is particularly useful for large tables, as it can significantly improve performance.
8. Transformation and Filtering:
- Kafka Connect provides built-in Single Message Transforms (SMTs) that can be applied to the data as it flows through the connector. This allows you to filter, modify, or enrich the data before it is sent to Kafka topics.
9. Security:
- The connector supports SSL/TLS for secure communication with the database.
- Authentication mechanisms such as username/password are supported for connecting to the database.
Microsoft SQL Server database and table readniess
CREATE DATABASE Test_DB;
GO
USE Test_DB;
CREATE TABLE Employee (
id INTEGER IDENTITY(1001,1) NOT NULL PRIMARY KEY,
first_name VARCHAR(255) NOT NULL,
last_name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL UNIQUE
);
INSERT INTO Employee(first_name,last_name,email) VALUES(‘RAM’,‘JA’,‘ram.ja@gmail.com’);
After deploying above script , you can access the table and data


Integrate JDBC Driver
- Download driver from this url JDBC Connector (Source and Sink)
- We have already mounted the local folder to Docker.

3. Download and extract and copy driver to local data folder then this automatically mount to kafka connect server
Deploy Connector
You can use any method to send push request. you can deploy with curl on terminal or you can use any restapi tools like insomnia to deploy the connectors
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors -d '{
"name": "jdbc_source_sqlserver_increment-v1",
"config":
{
"name":"jdbc_source_sqlserver_increment-v1",
"connector.class":"io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url":"jdbc:sqlserver://mssql;DatabaseName=Test_DB;",
"connection.user":"sa",
"connection.password":"YourStrong@Passw0rd",
"table.whitelist":"Employee",
"mode":"incrementing",
"incrementing.column.name":"id",
"topic.prefix":"sqlserver-."
}
}';Key Parameters:
connector.class: The class for JDBC source connector.connection.url: JDBC connection URL for SQL Server.mode: The mode to use for the connector (e.g.,bulk,incrementing,timestamp,timestamp+incrementing).incrementing.column.name: The column used for incrementing mode.timestamp.column.name: The column used for timestamp mode.table.whitelist: A list of tables to include.topic.prefix: Prefix for Kafka topics created.
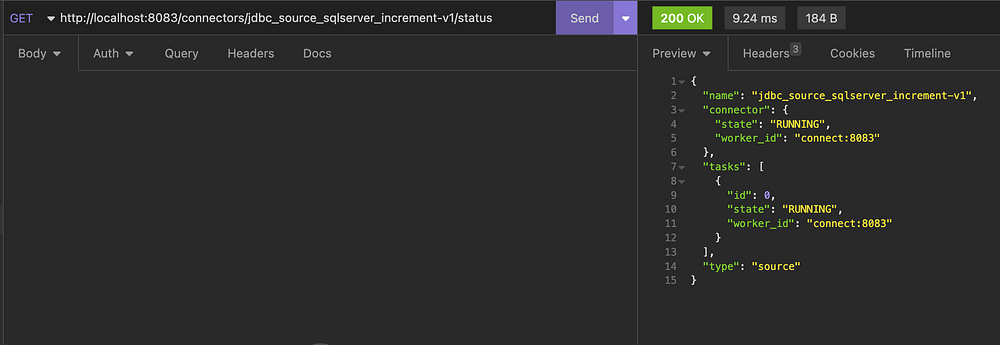
Connector Status
you can use insomnia to check the connector status or you can use CURL also
Kafka Topic Data validation

Troubleshooting
- Common Issues:
- Ensure the JDBC driver is correctly placed in the Kafka Connect classpath.
- Check the connection URL and authentication credentials.
- Verify the table and column names in SQL Server.
- Monitor Kafka Connect logs for errors.
Conclusion
In this article, we thoroughly explored the process of ingesting data from SQL Server into Kafka using the JDBC source connector. We covered the necessary configurations, setup, and key considerations to ensure a smooth and reliable data pipeline. From setting up the connector to troubleshooting common issues, this guide should have provided you with a solid foundation for integrating SQL Server with Kafka.
In our next article, we will delve into the implementation of the Kafka to Snowflake sink process. We will cover how to configure the Snowflake sink connector, manage data transformations, and ensure efficient data delivery from Kafka topics into Snowflake tables. This step-by-step guide will help you set up a robust data pipeline that seamlessly moves data from Kafka to Snowflake, enabling real-time analytics and business insights. Stay tuned!
If your testing process is successful, you’re all set! Should you encounter any issues, our team is readily available to provide guidance and support with a prompt response. Please do not hesitate to reach out to us at any time contact@accentfuture.com
Wishing you continued success in your coding endeavors 🚀.


